Despite the grandiose title, this post is pretty specific: converting RegExRX files to Markdown so I can include them in my nvALT snippets collection. Despite that, I’m sharing it because you can use it as a base to modify and start “rescuing” your own data out of other applications. I understand why applications of any complexity store their data in structured files, whether XML, JSON, or a database format, but I like to keep my data portable. Since the Data Liberation Army isn’t huge in number, the onus falls on us to find our own ways.
This script specifically works with XML and outputs to Markdown, but you could easily make the idea work with JSON files, binary XML (with a little help from plutil), or SQLite database queries, and output to any format you wanted with a little templating.
Ok, diatribe over. Back to the script.
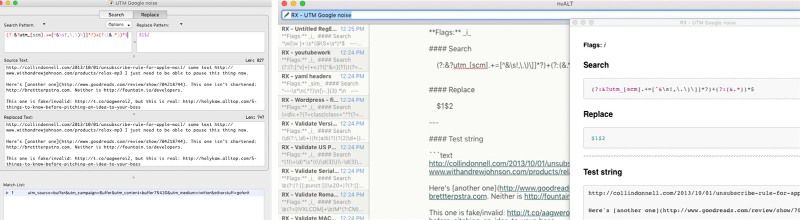
Out of all the editors/testers for regular expressions out there, I’ve always come back to RegExRx. It’s not pretty (the Mac App Store icon couldn’t even get shadow transparency right), but it has all the features I could ask for. As I work, I save my successful regular expressions to RegExRX files. These are plain text XML files with the patterns stored as hex. This makes them pretty human-unreadable, and you know me…
I wrote a script to convert a folder full of these .regexrx files to Markdown files I could drop into nvALT or Quiver. I won’t go into a ton of detail on this because I’m pretty sure there aren’t more than 5 people in the world who will ever need this script, but…
In this script, you can specify a few options when you run it:
$ regexrx2md.rb -h
Usage: /Users/ttscoff/scripts/regexrx2md.rb [OPTIONS]
-o, --output-dir=DIRECTORY Output folder, defaults to "markdown output"
-p, --prefix=PREFIX Prefix added before output filenames
-t, --template=TEMPLATE Use alternate ERB template
-h, --help Display this screen
Specify an output folder, a note title prefix, and your own template for the output (there’s a default one if you don’t make your own). A template is an ERB file that uses the variables @title, @flags, @search, @replace, and @source. The @source one is the contents of the “source text” in RegExRX, a string or text block to test the expression against. There are also helpers like “@source.indent” which will take every line and indent it 4 spaces (to make a Markdown code block). Also, .to_js simply replaces forward slashes with \/ so you can use /[search]/ in your template. Note that it doesn’t account for already-escaped slashes because I don’t use them in RegExRX (its copy-as feature does it automatically), but that’s something I’ll probably fix sooner than later.
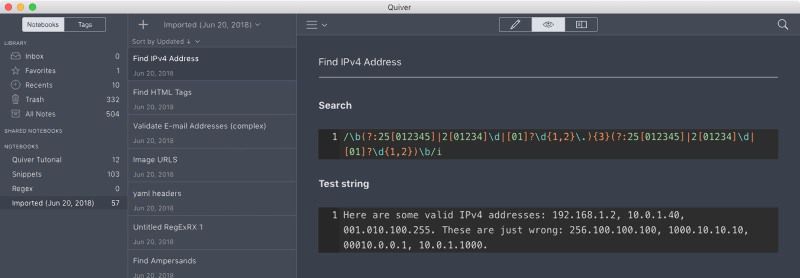
Here’s an example template that imports nicely into Quiver:
Side note: annoyingly, a lot of other snippet apps (like SnippetsLab) can’t just import Markdown files as notes. I had to import the results of this script in Codebox (which I think is now defunct) and then import that library in SnippetsLab.
And here’s the Ruby script. You need to have Nokogiri installed, which is (usually) just a matter of running gem install nokogiri (though depending on your setup you may need sudo gem install nokogiri and there’s a 50% chance you run into issues with libXML that you’ll have to search the web about).
#!/usr/bin/env rubyrequire'fileutils'require'nokogiri'require'optparse'require'erb'defclass_exists?(class_name)klass=Module.const_get(class_name)returnklass.is_a?(Class)rescueNameErrorreturnfalseendifclass_exists?'Encoding'Encoding.default_external=Encoding::UTF_8ifEncoding.respond_to?('default_external')Encoding.default_internal=Encoding::UTF_8ifEncoding.respond_to?('default_internal')endclassStringdefunpack[self].pack('H*')enddefindentout=''self.split("\n").each{|line|out+=" #{line}\n"}outenddefto_jsself.gsub(/(?mi)(?<!\\)\//,'\/')endendclassRegexRXattr_reader:title,:search,:flags,:replace,:sourcedefinitialize(file)doc=File.open(file){|f|Nokogiri::XML(f)}@content=doc.xpath('RegExRX_Document')@title=doc.xpath("//Window").first["Title"].strip@search=grabString('fldSearch')@flags=''@flags+='s'ifgrabOpt('Dot Matches Newline')@flags+='i'unlessgrabOpt('Case Sensitive')@flags+='m'ifgrabOpt('Treat Target As One Line')if@flags.length==0@flags=falseend# @regex = '/' + @search + '/' + @flagsifgrabPref('Do Replace')@replace=grabString('fldReplace')else@replace=falseend@source=falsesource=grabString('fldSource')ifsource.length>0@source=sourceendenddefto_markdown(template)out=ERB.new(template).result(binding)out.force_encoding('utf-8')enddefgrabString(name)out=@content.xpath("//Control[@name=\"#{name}\"]").first.content.strip.force_encoding('utf-8')out.unpackenddefgrabPref(name)@content.xpath("//Preference[@name=\"#{name}\"]").first["value"]=="true"enddefgrabOpt(name)@content.xpath("//OptionMenu[@text=\"#{name}\"]").first["checked"]=="true"endendoptions={}optparse=OptionParser.newdo|opts|opts.banner="Usage: #{__FILE__} [OPTIONS]"options[:prefix]=''options[:output]='markdown output'opts.on('-o','--output-dir=DIRECTORY','Output folder, defaults to "markdown output"')do|output|options[:output]=outputendopts.on('-p','--prefix=PREFIX','Prefix added before output filenames')do|prefix|options[:prefix]=prefix.strip+' 'endoptions[:template]=nilopts.on('-t','--template=TEMPLATE','Use alternate ERB template')do|template|options[:template]=templateendopts.on('-h','--help','Display this screen')doputsoptsexitendendoptparse.parse!default_template=<<-ENDOFTEMPLATE# <%= @title %><% if @flags %>**Flags:** _<%= @flags %>_<% end %>**Search:**<%= @search.indent %><% if @replace %>**Replace:**<%= @replace.indent %><% end %><% if @source %>---## Test string:```text<%= @source %>```<% end %>ENDOFTEMPLATE# If ERB template is specified, use that instead of the defaultifoptions[:template]ifFile.exists?(File.expand_path(options[:template]))&&File.basename(options[:template])=~/\.erb$/template=IO.read(File.expand_path(options[:template]))else$stderr.puts%Q{Specified template "#{options[:template]}" is not a valid template}Process.exit1endelsetemplate=default_templateendFileUtils.mkdir_p(options[:output])unlessFile.exists?(options[:output])Dir.glob('*.regexrx').each{|file|# $stderr.puts "Reading #{file}"rx=RegexRX.new(file)filename=File.join(options[:output],options[:prefix]+rx.title+'.md')File.open(filename,'w'){|f|f.print(rx.to_markdown(template))}$stderr.puts"Regex written to #{filename}"}
Even if you don’t use RegExRX, I hope this inspires some data liberation for some folks.