I tend to spend a couple hours every weekend hacking new features into this website. A lot of them are convenience features on the back end that really have no visible effect on the user experience, but some of them do. I think a lot of them fly under the radar. In order to make myself feel a little better about the time invested, as well as helping me to remember what all I’ve done, I thought I’d point out a few of the prominent, front-facing “tricks.”
I’m happy to share the techniques behind any of these, but will conserve writing time and wait for any specific requests to come up before I decide what’s worth a post. Feel free to leave a comment here or ping me on Twitter about anything you’d like more detail on.
The box at the top of the homepage is driven by a background process that polls every hour to see which of the last 40 posts have the most links on Twitter, which I’ve found to be a pretty accurate gauge of popularity. It caches straight HTML and loads it asynchronously after the page load is complete.
Web Excursions
The web excursions are powered by a Pinboard tag (“blogit”) and a local script which waits for five links with that tag to accumulate before generating a draft post. I just edit the post for any corrections and hit publish. jTag and Zemanta handle adding keywords, and boilerplate text is inserted at the beginning of the permalink page during page render based on YAML header tags.
Open Graph
Twitter cards, Facebook embeds and other social sharing metadata is handled via simple plugins which do things like extracting the first image from the post, detecting YouTube embeds and generating keywords and descriptions from summarized text. If I include a file with the same name as the first image but with “_lg” at the end and before the extension, that version is used for the image share. In reality, I just have an htaccess rule that always uses “image_lg.png” as the embed image, but if the file doesn’t exist it serves the regular-sized image under that name.
Downloads manager
The download box you see at the bottom of posts with related scripts or applications is driven by a downloads manager that I’ve written about before. It uses a CSV file which I can update at any time to regenerate all of the links to a download across the site to the latest version. It also works with external links such as GitHub zipballs.
I have new Rake tasks that make it easier than ever to add and update downloads without directly editing the CSV file.
Lazy loading images and YouTube videos
My current img tag for Jekyll creates grey-box images with data attributes for the original source. When you scroll close enough to an off-screen image, it replaces the grey box with the original. By generating size tags I can do this without affecting page layout as the final images load. My image upload tool automatically generates the dimensions after compressing the image, so this basically an automatically-maintained feature.
When the Atom feed is generated, a simple regular expression replaces the grey box image with the original source so that images still show up in feeds.
Infinite scroll
This one is a little pointless, but I spent some time adding “infinite scroll” to the homepage. When you scroll to the bottom, it will load the next page of posts inline so you can basically scroll through the entire site without leaving the page. I attempted to add a back button to it so that if you did click into an article, going back would bring you to the original point in the infinite list. That was only mildly successful.
Lazy loading of images and other features is maintained even on newly loaded sections.
Collapsing sidebar
You may have noticed that — at certain screen sizes — scrolling down the page causes the sidebar to “collapse” to a minimal size. In my opninion, this improves readability while still maintaining navigation capability.
Headline icons
On most of the index pages, you’ll see small icons next to the headlines, indicating “Review,” “Code,” “Podcast,” etc. These are icon fonts that are placed via a class name applied based on YAML headers. I can specify these manually, or have them automatically suggested at publish time based on jTag and Zemanta results.
Responsive layout
If you haven’t tried the site on both iPhone and Desktop, a lot of care was taken to make it work on both. I’m still quite unhappy with portrait iPad layout, but at other breakpoints I think it works pretty well. Other features are enabled and disabled based on detected viewport dimensions.
Post series
I have a “series” plugin built that takes a series title from YAML headers and generates both an index page (currently under the “Series” tab on the Topics page) and in-post links to other posts in the series. The in-page version is in chronological order and highlights the current location in the series.
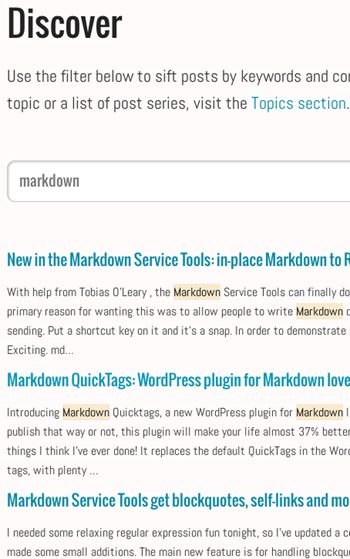
Filtering in Discover/Search
In the Discover page (and as of recently the search page), you can type keywords and have matching posts filter to the top. This is based not just on titles, but also on keywords and full-text search, weighted for title matches, tag matches and text matches in that order. Both pages accept a “q” query parameter to automatically populate and run the search, making it a viable replacement for site search.
I’ve tried quite a few approaches to this and am currently using a Ruby script as a CGI to parse a JSON file that I generate with each page build. I’ve also worked with creating the search entirely in JavaScript — reading a slightly pared-down JSON file — but ran into eventual performance issues. I’m sure this will evolve as I come up with better search algorithms.
nvALT links
If you click on the gear in the upper right and turn on “nvALT Links,” you get a link in the top meta portion of each post that will automatically add the post to nvALT for you as pure Markdown.
SuperReadable
From the same gear menu, you can also enable SuperReadable mode, which slightly alters the contrast of the page and turns on OpenDyslexic as the copy font. It’s a little jarring at first, but it aids me (a non-dyslexic) in faster reading and comprehension.
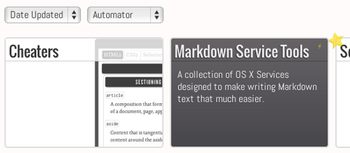
Projects page
The projects page has some nifty animations and a way to sort/filter the projects based on most recent activity and general topics. Each individual project includes a tag-based list of posts related to the project. Stars on the index page indicate whether I personally still consider a project “active” or not.
The project index page and all individual project pages are generated from a folder full of Markdown files. Each file contains the necessary YAML headers to create its entry on the index page and generate the page itself with related posts and extra links. The file can also consist of just YAML headers and an external link, if the index entry is linked to a Github or other page instead of a project page. All project pages and the index are generated via a single plugin.
Topics filter
The Topics page is basically a tag cloud. It has three tabs. The first tab lists the top tags based on how many times they’re used in posts. The second tab lists every tag on the site, and you can filter it quickly from the search box to avoid scrolling a fairly long page.
Table of Contents
I forgot to mention the Table of Contents feature when I first published this post. On longer posts I can include a :toc tag that my renderer of choice (Kramdown) turns into a table of contents based on headers in the document (shown on this post, for example, and on most project pages). jQuery Waypoints watches for a scroll past the location of the TOC in the document and moves it to a floating bar in the upper right which can be used to navigate the article. This is all done with a bit of JavaScript and a lot of CSS.
Donate button tag
I happen to really like the Donate button system. I can include a donate tag with optional message and unique Paypal ID, and have an animated donation link added to any post or page. Here’s a working version with custom message, feel free to click it. What happens after that is your business.
There’s more, and I try to keep track of my little hacks using a Day One tag called “jekylljournal.” If there’s anything here you’re curious for more info about, let me know.